2025 is the year enterprises take control of their AI stack—and open-source LLMs are leading the charge.
Businesses no longer want to rent intelligence. They want to own, shape, and secure it. At MeisterIT Systems, we understand that selecting the right open-source LLM isn’t just about performance benchmarks. It’s about strategic alignment, data control, and building scalable, domain-aware AI solutions.
In this guide, we break down top open-source LLMs, their ideal use cases, and how to evaluate them with confidence.
Understanding Open-Source LLMs
An open-source LLM is a large language model, with its architecture, training weights, and data all available to the public. This transparency encourages research collaboration, enhances auditability, and provides businesses with the flexibility to customize or fine-tune the model according to their specific needs.
In contrast, closed-source models like OpenAI’s GPT-4 or Anthropic’s Claude restrict access to internal workings and usage rights. With open-source models, you have complete control over how the model is hosted, how it’s used, and how it’s improved over time.
Why Open-Source LLMs Matter in 2025
AI is becoming foundational to modern products and platforms. From automating customer service to powering intelligent search or building personalized assistants, AI is now a capability, not just a feature.
That’s why enterprises are looking beyond prebuilt APIs and exploring how to own their AI stack. Open-source LLMs are central to that shift.
Here’s why they matter:
- Cost Control: Avoid recurring API or licensing fees.
- Data Privacy: Keep data in-house with on-prem or private cloud deployment.
- Custom Fine-tuning: Tailor the model to domain-specific datasets.
- Model Transparency: Understand and inspect how your AI makes decisions.
- Deployment Flexibility: Run the model on cloud, edge, or internal servers.
By 2025, open-source models will no longer be just for experimentation. They’re being used in production by global enterprises, governments, and startups alike.
Popular Open-Source LLMs in 2025
Whether you’re deploying AI in production or exploring models for internal tools, the best open-source LLMs in 2025 offer a mix of performance, flexibility, and ease of integration. Below is a detailed look at some of the most powerful and widely used open models today.
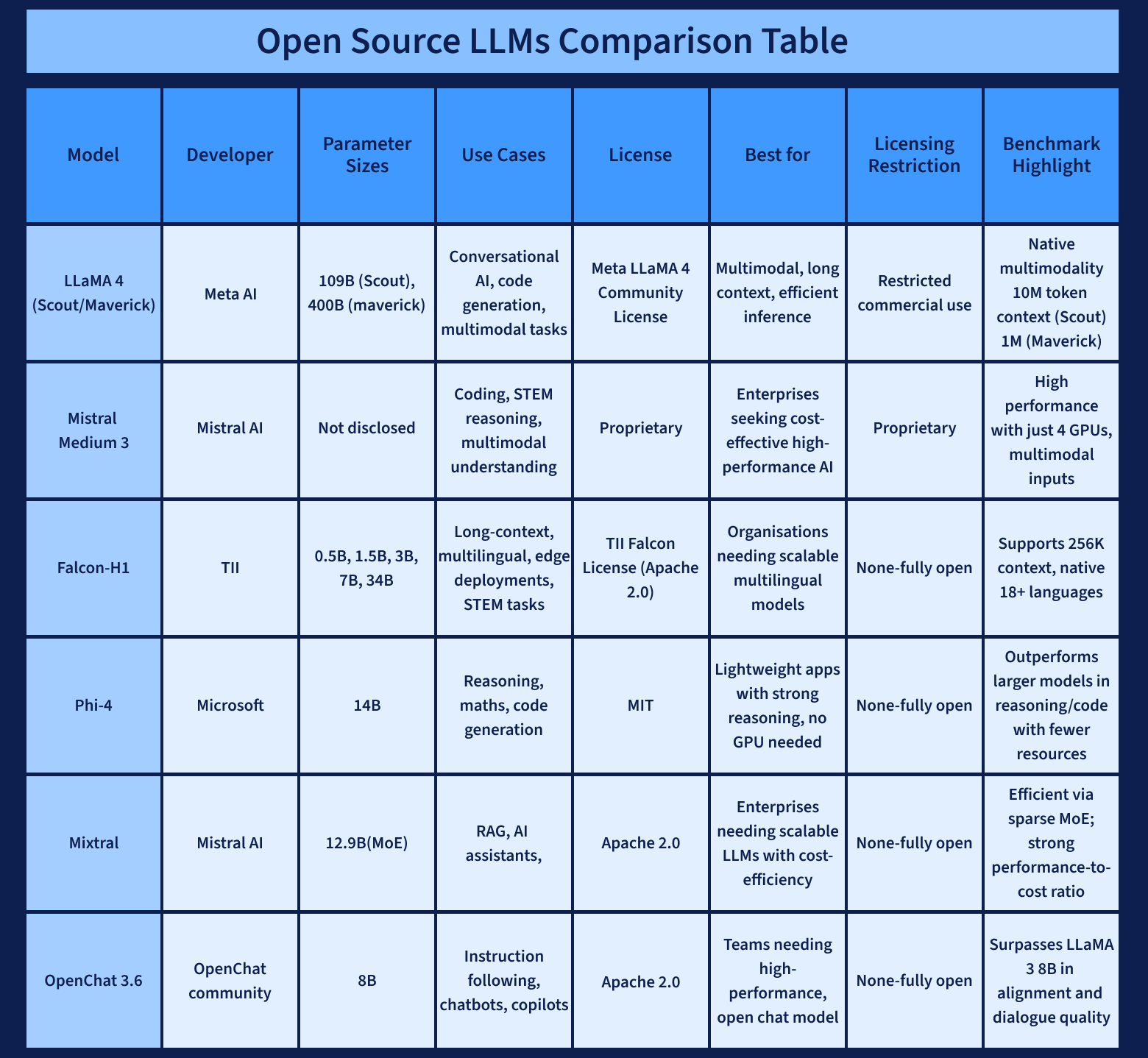
1. LLaMA 3 by Meta AI
- Developer: Meta AI
- Sizes Available: 8B, 13B, 70B parameters
- License: LLaMA 3 Community License (limited commercial use)
- Best For: Research, chatbots, educational tools, multilingual tasks
LLaMA 3 is one of the most reliable open-source LLM families available in 2025. It’s designed to perform well across different tasks and supports multiple languages. With different model sizes, teams can choose the version that fits their hardware and use case needs.
Key Features:
- Comes in three sizes for different deployment needs
- Strong results in language tasks like summarization, question answering, and chat
- Includes fine-tuned versions for specific tasks (e.g., instruct models)
- Supported by an active community and tools on platforms like Hugging Face
Use Cases: Virtual assistants, support chatbots, educational tutors, and content summarization tools
2. Mixtral 8x7B by Mistral AI
- Developer: Mistral AI
- Size: 12.9B active parameters (uses Mixture of Experts)
- License: Apache 2.0 (fully open for commercial use)
- Best For: Enterprise assistants, high-traffic apps, RAG systems
Mixtral is built using a sparse architecture called Mixture of Experts (MoE), which activates only a few parts of the model during each request. This makes it fast and efficient while still delivering high-quality responses. It’s ideal for applications that need to scale without high compute costs.
Key Features:
- Optimized for fast inference and low infrastructure costs
- Performs well in long conversations and multi-step reasoning
- Easy to integrate with popular tools like LangChain and vLLM
- Open license makes it business-friendly
Use Cases: Enterprise knowledge assistants, scalable chat systems, automation workflows, and RAG-based tools
3. Falcon-H1 by TII (Technology Innovation Institute)
- Developer: TII
- Sizes: 0.5B, 1.5B, 3B, 7B, 34B
- License: Apache 2.0-based (open for commercial use)
- Best For: Multilingual apps, long-document processing, edge deployment
Falcon-H1 is designed for flexibility. It combines traditional transformer technology with a newer architecture called Mamba, which makes it great at handling long inputs. It’s also efficient enough to run on edge devices or internal servers.
Key Features:
- Supports very long input text (up to 256K tokens)
- Available in several sizes for different hardware capabilities
- Multilingual support built-in (18+ languages)
- Good performance with limited computing resources
Use Cases: Policy document analysis, multilingual customer service, legal content parsing, private deployments
4. Command R+ by Cohere for AI
- Developer: Cohere for AI
- Sizes: Not disclosed
- License: Apache 2.0 (fully open for business use)
- Best For: Retrieval-Augmented Generation (RAG), enterprise search, Q&A bots
Command R+ is built specifically for use with RAG setups, where AI uses external data sources to improve response quality. It integrates well with vector databases and provides accurate, context-aware answers.
Key Features:
- Designed to work with vector databases like Pinecone and Weaviate
- Strong at combining retrieved documents with AI reasoning
- Performs well in enterprise search and document-heavy tasks
- Suitable for production use with flexible licensing
Use Cases: Company knowledge bots, internal helpdesk AI, legal and HR document search, content recommendation tools
5. OpenChat 3.6 (8B) by OpenChat Community
- Developer: OpenChat Community
- Sizes: 8B parameters
- License: Apache 2.0 (commercial-friendly)
- Best For: Custom chatbots, instruction-following agents, copilots
OpenChat 3.6 is based on Meta’s LLaMA 3 model but fine-tuned to follow instructions and handle conversational tasks more effectively. It’s designed to provide safer, more accurate answers and is lightweight enough to run on modest hardware.
Key Features:
- Aligned to follow user instructions clearly
- Competitive with larger models in dialogue tasks
- GGUF format support for easier deployment
- Actively improved by an open-source community
Use Cases: Customer chatbots, employee-facing copilots, healthcare assistants, internal knowledge bots
6. Phi-4 by Microsoft
- Developer: Microsoft
- Sizes: 14B parameters
- License: MIT (fully open for commercial and personal use)
- Best For: Reasoning, code generation, lightweight applications
Phi-4 is a small but powerful model that focuses on reasoning and logic-heavy tasks. It performs well on math and programming problems and is efficient enough to run on CPU-based systems.
Key Features:
- Small size, high accuracy on complex tasks
- Outperforms larger models in reasoning benchmarks
- Optimized for use on edge devices or even in browser-based tools
- An open license allows full flexibility
Use Cases: Math solvers, code generation tools, educational apps, and smart features in lightweight software
7. LLaMA 4 – Scout & Maverick
- Developer: Meta AI
- Sizes: Scout (109B total), Maverick (400B total)
- License: Expected to follow LLaMA Community License
- Best For: Long-context, multimodal AI, enterprise-grade systems
LLaMA 4 brings powerful new capabilities with support for both text and images. Built with a Mixture of Experts architecture, these models are designed for next-generation use cases like enterprise copilots, complex reasoning, and multimodal input handling.
Key Features:
- Can handle up to 10 million tokens in a single input
- Processes both text and image inputs
- Optimized for performance with lower active parameter usage
- Built for enterprise and research-grade AI solutions
Use Cases: Enterprise knowledge agents, AI copilots for coding, multimodal chat systems, advanced document understanding
Key Factors to Evaluate an Open-Source LLM
Not every model fits every use case. Here’s how to evaluate your options:
1. Model Size and Efficiency
Bigger doesn’t always mean better. You need to balance capability with compute cost. Smaller models like 7B or 13B are often good enough for enterprise workflows and faster to fine-tune.
What to consider:
- Inference latency
- Memory and GPU requirements
- Throughput for concurrent users
2. Training Data Quality
The quality of a model’s training data impacts its reasoning, coherence, and output accuracy.
Why it matters:
- Public models may include biased or noisy data
- Fine-tuning on curated datasets improves relevance
- Domain-specific tuning reduces hallucinations
3. Licensing
Make sure the license allows for commercial use. Some models are restricted for research purposes only.
Tip: Prefer models under Apache 2.0 or MIT licenses for flexibility.
4. Community and Ecosystem Support
Models with active communities, tooling, and documentation are easier to adopt and scale.
Watch for:
- Hugging Face integration
- Open-source inference frameworks (vLLM, TGI, etc.)
- Availability of fine-tuned checkpoints
5. Evaluation Benchmarks
Use standard benchmarks like MMLU, TruthfulQA, and ARC to compare model performance across reasoning, math, and factual accuracy.
Internal testing is also key: Build a simple QA or RAG prototype to test how well the model handles your use case.
When to Fine-Tune vs. Use Off-the-Shelf
Some use cases demand fine-tuning, while others work well with prompt engineering or RAG pipelines.
Use the model as-is when:
- You’re building a general-purpose chatbot or assistant
- Speed to market is a priority
- Your use case doesn’t require deep, domain-specific knowledge
Fine-tune the model when:
- You need it to understand industry- or business-specific language
- You’re developing internal tools like support ticket triage or custom workflows
- Brand consistency in tone, style, or format is important
Best Practices for Deploying Open-Source LLMs
Once you’ve chosen your model, here’s how to move toward production safely and efficiently.
1. Optimize Inference
Use frameworks like vLLM, TGI, or ONNX Runtime to reduce latency and maximize GPU usage.
2. Add Guardrails
Use tools like Guardrails AI, Rebuff, or LangChain to manage model behavior and catch harmful outputs.
3. Use Vector Search for RAG
Combine open-source LLMs with tools like Pinecone, Weaviate, or Qdrant to enable Retrieval-Augmented Generation for more accurate responses.
4. Monitor and Evaluate
Track metrics like:
- Token usage per query
- Response accuracy
- Latency
- User feedback
Monitoring helps you improve the system iteratively.
Partner with MeisterIT Systems for AI Integration
Selecting the right open-source LLM is only the first step. Successful implementation requires a clear strategy, the right infrastructure, and strong technical capabilities.
At MeisterIT Systems, we help you integrate LLMs securely and effectively into your existing workflows. Whether you want to build custom chatbots, automate content workflows, or create internal knowledge assistants, our AI team brings the tools and support to make it happen.
Ready to get started? Contact us for a free consultation.